Willkommen zurück! In den letzten Monaten habe ich mich intensiv mit den Problemen rund um Halluzinationen in generativen KI-Modellen und der Herausforderung der Kontextualisierung beschäftigt – Themen, die ich in meinem letzten Artikel ausführlich behandelt habe. Die Auseinandersetzung mit diesen Fragen hat mir gezeigt, dass eine robuste Kombination aus Retrieval und Generierung, also ein sogenanntes Retrieval Augmented Generation (RAG), oftmals die einzige Möglichkeit ist, um verlässliche und fachlich korrekte Ergebnisse zu erzielen. Dabei stieß ich in meinem beruflichen Alltag auf eine Anforderung, die exakt auf diese Problematik abzielt: Die Notwendigkeit, technische Dokumentationen einer umfangreichen Software präzise und aktuell darzustellen, ohne dass wichtige Zusammenhänge verloren gehen oder gar falsche Inhalte generiert werden.
Diese Anforderung veranlasste mich, eine maßgeschneiderte RAG-Lösung zu entwickeln, die auf modernen Tools wie n8n, Supabase und Crawl4AI basiert. In den folgenden Abschnitten möchte ich jede Komponente der Lösung detailliert vorstellen und dabei auch auf vergleichbare Projekte aus der Open-Source-Community eingehen – Projekte, die ähnliche Ansätze verfolgen, wie beispielsweise das Repository super-rag von superagent-ai oder arguflow/arguflow. Auch RAGFlow, wie es auf ragflow.io vorgestellt wird, sowie weitere Repositories wie philfleck/ragrug und AndreasX42/RAGflow bieten spannende Einblicke in die Entwicklung und Optimierung von RAG-Systemen.
Diese Lösung hat ihren Ursprung in einem realen Anwendungsfall, bei dem es darum ging, umfangreiche Softwaredokumentationen zu verarbeiten, zu indexieren und in einem interaktiven Chat-anwendungsfreundlich darzustellen – ohne, dass dabei die Gefahr von „Halluzinationen“ in der generierten Ausgabe besteht. Mit Hilfe von n8n als Automatisierungswerkzeug, Supabase als skalierbare Datenbanklösung und Crawl4AI als Crawler, der relevante Datenquellen durchforstet und für den Weiterverarbeitungsprozess aufbereitet, entstand ein mehrstufiges System. Jede Komponente spielt dabei eine zentrale Rolle: Der Crawler sammelt und extrahiert Inhalte, n8n orchestriert die einzelnen Verarbeitungsschritte und Supabase stellt die Speicher- und Abfragefunktionalitäten, insbesondere durch den Einsatz von Vektorisierungstechniken, bereit. In diesem Zusammenhang ist es mir auch gelungen, den üblichen Problemen der Halluzinationsproduktion weitgehend entgegenzuwirken, da die Generierung immer auf validierte und kontextuell passende Daten zurückgreifen kann.
Im Folgenden gehe ich zunächst auf die Einrichtung von Crawl4AI ein, das als erster Baustein dieser Architektur dient. Ich werde detailliert beschreiben, wie ich es auf einem eigenen Server installiert habe, wie ein nginx Proxy eingerichtet wurde und welchen Stellenwert dabei ein Lets Encrypt SSL-Zertifikat hat, um eine sichere Verbindung zu garantieren. Das darauffolgende Kapitel widmet sich dem Aufbau einer RAG-Datenbank mittels eines n8n Workflows in Verbindung mit Supabase, in dem anhand einer speziellen Sitemap für die Softwaredokumentation sämtliche Inhalte intelligent gecrawlt, vektorisiert und abgespeichert werden. Den abschließenden Teil des Artikels bildet der Einsatz eines weiteren n8n Workflows zur Umsetzung eines interaktiven Chats: Hier wird die Kommunikation mit einem KI-Agenten ermöglicht, der die relevanten Daten aus Supabase abruft und sie in Form von präzisen, kontextbezogenen Antworten an den Benutzer zurückliefert. Ein besonderes Highlight ist dabei die Implementierung eines Tools, das die Metainformationen der Dokumentationsseiten als direkte Quellen verlinkt, was nicht nur Transparenz schafft, sondern auch dem Anwender die Möglichkeit bietet, tiefere Einblicke in die jeweiligen Themenfelder zu gewinnen.
Die Entscheidung, n8n als Workflow-Orchestrator zu wählen, basiert vor allem auf dessen Flexibilität und Erweiterbarkeit. Mit n8n lassen sich komplexe Prozesse visuell und modular darstellen, was gerade in multidisziplinären Projekten, in denen Daten aus unterschiedlichen Quellen zusammenlaufen, einen erheblichen Vorteil darstellt. Ergänzt wird dies durch Supabase, das als modernes Backend dient und dank der Möglichkeit, Vektordaten effizient zu speichern und abzufragen, eine ideale Ergänzung für den Aufbau einer Suchinfrastruktur bietet, die semantische Abfragen ermöglicht. Crawl4AI – ein speziell entwickelter Crawler – übernimmt dabei die Aufgabe, Daten aus verschiedensten Quellen aufzubereiten und gemäß den Anforderungen der Softwaredokumentation zu extrahieren. Die enge Verzahnung zwischen diesen Komponenten ermöglicht es, stets aktuelle und relevante Informationen bereitzustellen, ohne dass dabei die Gefahr einer fehlerhaften Dateninterpretation oder unerwünschter Halluzinationen besteht.
Die Interoperabilität zwischen den einzelnen Systemen war dabei stets eine große Herausforderung. Die verschiedenen Komponenten – n8n, Supabase und Crawl4AI – wurden ursprünglich als isolierte Werkzeuge konzipiert, mussten jedoch in diesem Projekt eng miteinander verzahnt werden, um einen nahtlosen Informationsfluss zu ermöglichen. Daher war es essenziell, über ein exzellentes Fehler- und Ausnahmehandling zu verfügen, das mögliche Inkonsistenzen oder Verzögerungen frühzeitig erkennt und behebt. Mit den oben erwähnten Tools konnte eine skalierbare und ausfallsichere Lösung realisiert werden, die sich auch in produktiven Umgebungen mühelos bewährt. Die dabei gewonnenen Erfahrungen und Erkenntnisse sind nicht nur für den konkreten Anwendungsfall von unschätzbarem Wert, sondern bieten auch einen interessanten Ausgangspunkt für zukünftige Projekte, bei denen eine hohe Datenqualität und Zuverlässigkeit von zentraler Bedeutung sind.
Die Relevanz der Thematik und die Vielschichtigkeit der Herausforderung macht deutlich, warum der Aufbau eines stabilen RAG-Systems gerade jetzt von so großer Bedeutung ist. Mit dem Siegeszug generativer KI-Systeme stehen Unternehmen und Entwickler vor der Aufgabe, die Balance zwischen Kreativität und Faktenstreue zu finden – ein Balanceakt, der in meinem beruflichen Alltag unmittelbar spürbar ist. Insgesamt hat mich diese Projektarbeit nicht nur in technischer Hinsicht bereichert, sondern mir auch gezeigt, wie wichtig es ist, bei der Entwicklung von KI-Systemen immer einen Schritt voraus zu denken und bestehende Methoden kontinuierlich weiterzuentwickeln.
Im Vergleich zu Ansätzen, die ausschließlich auf generative Modelle setzen, hat meine Lösung den Vorteil, dass sie auf einem soliden Fundament verifizierter Daten aufbaut. Dies ist der Schlüssel zur Minimierung von Fehlern und zur Steigerung der Gesamtzuverlässigkeit des Systems. Letztlich zeigt sich, dass die enge Verzahnung von Crawler-Technologien, Workflow-Automatisierung und moderner Datenbankarchitektur zu einer signifikanten Verbesserung der Systemstabilität und Datenintegrität führt – ein Befund, der in der aktuellen Forschung und Praxis gleichermaßen Bedeutung findet.
Im Folgenden soll nun die technische Umsetzung im Detail vorgestellt werden, um euch nicht nur theoretische Einblicke, sondern auch praktische Implementierungsbeispiele und Konfigurationsdateien an die Hand zu geben. Es folgt der erste Bestandteil des Systems: Die Implementierung von Crawl4AI auf einem eigenen Server.
Teil 1: Crawl4AI – Einrichtung und Konfiguration auf dem Eigenen Server
In diesem ersten technischen Abschnitt widme ich mich der Einrichtung und dem Betrieb von Crawl4AI, einer leistungsfähigen Komponente zur automatisierten Erfassung und Aufbereitung von Webseiteninhalten. Ziel dieser Komponente war es, die umfangreichen Informationen der Softwaredokumentation systematisch zu erfassen, zu parsen und in einem für weiterführende Prozesse optimal nutzbaren Format bereitzustellen. Dabei spielt die Übertragung der Daten in eine zentrale Datenbank eine tragende Rolle – insbesondere in Hinblick auf die spätere Vektorisierung und Integration in einen RAG-Workflow.
Die Implementierung von Crawl4AI auf einem eigenen Server bringt zahlreiche Herausforderungen mit sich, angefangen von der Einrichtung einer stabilen Hosting-Umgebung über die Konfiguration eines Reverse Proxys bis hin zur Einrichtung eines SSL-Zertifikats, das für eine sichere Verschlüsselung sämtlicher Datenströme sorgt. Ein zentraler Bestandteil dieser Umgebung ist der Einsatz von Docker Compose, der es ermöglicht, alle benötigten Dienste in Form von Containern zu orchestrieren und so eine konsistente sowie reproduzierbare Infrastruktur zu gewährleisten.
Technische Grundlagen und Systemarchitektur
Der erste Schritt bestand darin, den eigenen Server zu konfigurieren und alle notwendigen Softwarekomponenten zu installieren. Dabei wurde besonderes Augenmerk auf Stabilität, Skalierbarkeit und Sicherheit gelegt. Das grundlegende Systemsetup beinhaltete eine aktuelle Linux-Distribution, wobei Ubuntu 22.04 LTS bevorzugt wurde, da es eine langfristige Support-Version darstellt und sich hervorragend für produktionsreife Umgebungen eignet. Neben der Basisinstallation wurden alle sicherheitsrelevanten Updates durchgeführt und der Server für den produktiven Einsatz gehärtet.
Die gesamte Systemarchitektur gliedert sich in mehrere Ebenen. An oberster Stelle steht dabei der Webzugang über einen nginx Reverse Proxy, der eigens konfiguriert wurde, um den Traffic optimal zu verteilen, Anfragen zu terminieren und gleichzeitig als SSL-Terminator zu agieren. Hierzu kam Lets Encrypt zum Einsatz, das kostenfrei ausstellbare SSL-Zertifikate bereitstellt. Die Kombination aus nginx und Lets Encrypt sichert nicht nur den Datenverkehr, sondern ermöglicht auch eine einfache und automatisierte Erneuerung der Zertifikate, was gerade in produktiven Systemen von unschätzbarem Wert ist.
Einer der größten Vorteile der gewählten Architektur liegt in der Modularität: Alle Dienste – vom Webserver über den Reverse Proxy bis hin zu den einzelnen Containern, die Crawl4AI und damit verbundene Anwendungen hosten – werden über Docker Compose gesteuert. Dieser Ansatz erlaubt es, die gesamte Infrastruktur als Code zu verwalten, Änderungen reproduzierbar zu machen und auch in einer Continuous-Deployment-Pipeline zu integrieren.
Einrichtung des nginx Reverse Proxys und Lets Encrypt Zertifikats
Die Konfiguration des nginx Reverse Proxys stellte einen kritischen Punkt im Setup dar. Ziel war es, den Zugang zu den internen Docker-Containern sicher zu regeln und dabei die Flexibilität einer Container-basierten Infrastruktur zu bewahren. In der nginx-Konfiguration wurden mehrere Server-Blöcke definiert, die jeweils spezifische Subdomains für die einzelnen Dienste abbilden sollten. Dabei musste darauf geachtet werden, dass der interne Datenverkehr nur über sichere Kanäle erfolgt – daher wurde für jeden zugänglichen Dienst ein SSL-Zertifikat mittels Lets Encrypt eingerichtet.
Die Konfiguration sah in etwa folgendermaßen aus:
server {
server_name crawl.my-domain.de;
location / {
proxy_pass http://localhost:11235;
include proxy_params;
}
listen [::]:443 ssl ipv6only=on; # managed by Certbot
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/crawl.my-domain.de/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/crawl.my-domain.de/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server {
if ($host = crawl.my-domain.de) {
return 301 https://$host$request_uri;
} # managed by Certbot
listen 80;
listen [::]:80;
server_name crawl.my-domain.de;
return 404; # managed by Certbot
}
Diese Konfiguration stellt sicher, dass alle Anfragen über HTTPS laufen und die interne Kommunikation an den entsprechenden Container weitergeleitet wird. Neben dem grundlegenden Setup wurde auch ein automatisierter Prozess zur Zertifikatserneuerung eingerichtet, um administrativen Aufwand zu minimieren und Sicherheit kontinuierlich zu gewährleisten.
Herausforderungen im Betrieb und Lösungsansätze
Die Einrichtung eines solch komplexen Setup brachte naturgemäß auch einige Herausforderungen mit sich. Einer der ersten Kritikpunkte war die Synchronisation der Container untereinander. Bei Docker Compose ist das wichtigste das Port-Mapping. Hier solltet ihr darauf achten, wenn ihr mehrere Projekte auf dem gleichen Server laufen habt, dass diese sich nicht im Mapping überschneiden. In diesem Beispiel war das kein Problem, da ein eher exotischer Port verwendet wurde. Außerdem ein wichtiger Punkt sind in der Regel die definierten Volumes, um Datenverlust zu vermeiden, wenn man die Container mal stoppen muss. Da Crawl4AI ein eher zustandsloses System ohne Benutzernamen ist, kann hier das Volume im Arbeitsspeicher gehalten werden.
version: '3.8'
services:
crawl4ai:
image: unclecode/crawl4ai:all-amd64
ports:
- "11235:11235"
environment:
- CRAWL4AI_API_TOKEN=${CRAWL4AI_API_TOKEN:-} # Optional API security
- MAX_CONCURRENT_TASKS=10
# LLM Provider Keys
- OPENAI_API_KEY=${OPENAI_API_KEY:-}
- ANTHROPIC_API_KEY=${ANTHROPIC_API_KEY:-}
volumes:
- /dev/shm:/dev/shm
deploy:
resources:
limits:
memory: 8G
reservations:
memory: 2G
Weiterhin musste ich darauf achten, dass das System auch bei hoher Last stabil bleibt. Gerade der Crawler, der potenziell sehr viele Anfragen in kurzer Zeit verarbeiten muss, benötigte eine sorgfältige Konfiguration von Ressourcen. Es wurden Limits bezüglich Speicher und CPU-Ressourcen in Docker konfiguriert, sodass einzelne Container nicht den Gesamtbetrieb beeinträchtigen können. Gleichzeitig bot die Möglichkeit, Container horizontal zu skalieren, einen zusätzlichen Puffer gegen Lastspitzen.
Integration von Crawl4AI in den Gesamtworkflow
Nachdem die Basisinfrastruktur stand, erfolgte der nächste Schritt: Die Integration von Crawl4AI in den umfassenden Workflow zur Erstellung der RAG-Lösung. Crawl4AI ist dafür konzipiert, Webseiteninhalte automatisiert zu erfassen und in ein strukturiertes Format zu überführen. Der Crawler wurde dabei über die REST-API von den entsprechenden n8n-Knoten angesprochen. Die Datenquelle war dabei eine Sitemap der gewünschten Dokumentation, diese wurde in einer Schleife durchgelaufen, und jede Unterseite entsprechend gecrawlt. Dabei war etwas tüfteln angesagt, so dass z.B. nicht auf jeder Seite ein Glossar enthalten war, was die Genauigkeit der Suche natürlich verschlechterte. Außerdem habe ich über einen CSS-Selektor nur den Seiteninhalt gescannt, der auch wirklich relevant war. Das hilft auch den Speicherverbrauch in der Datenbank stark zu reduzieren.
Fazit Crawl4AI
Die Einrichtung von Crawl4AI auf einem eigenen Server erwies sich als ein anspruchsvoller, aber letztlich sehr lohnender Prozess. Durch den gezielten Einsatz moderner Technologien wie Docker Compose, nginx als Reverse Proxy und Lets Encrypt für den sicheren Betrieb konnte eine robuste, skalierbare Plattform geschaffen werden, die den Grundstein für den weiteren Aufbau eines leistungsfähigen RAG-Systems legt. Alle Komponenten arbeiten hier eng zusammen, um die Inhalte der Softwaredokumentation automatisiert zu erfassen, aufzubereiten und für die nachfolgenden Workflows verfügbar zu machen. Diese technische Basis bildet somit die Grundlage für die nächsten Schritte, in denen die gesammelten Daten in einem intelligenten n8n Workflow weiterverarbeitet und in eine Vektor-Datenbank integriert werden.
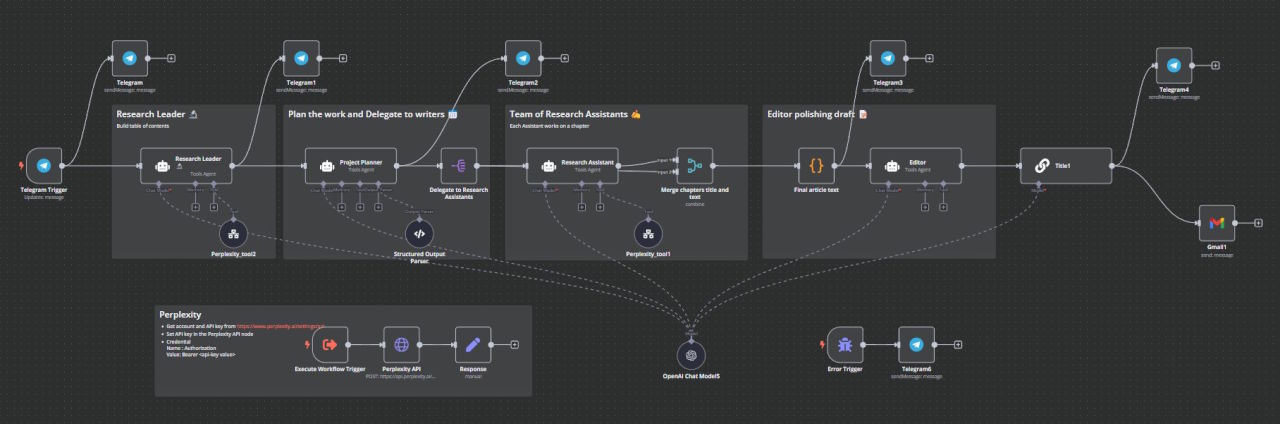
Hier das fertige Ergebnis aus n8n:
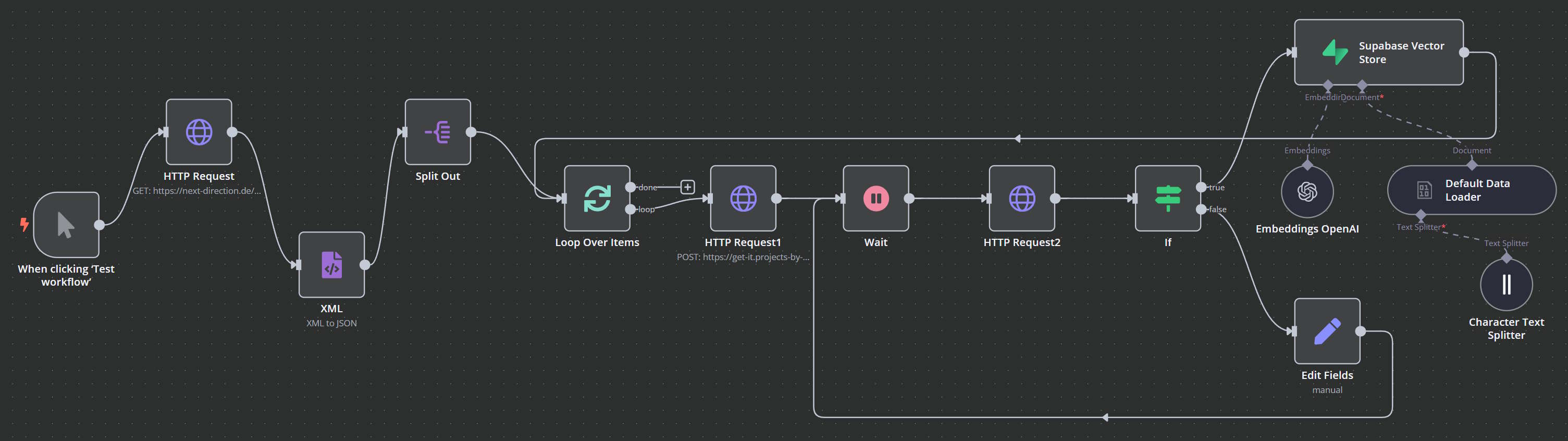
Teil 2: n8n Workflow für Aufbau einer RAG Datenbank mit Supabase Vektor Knoten
Nachdem die Sammlung und Aufbereitung der Daten mittels Crawl4AI und dem stabilen Hosting-Setup erfolgreich implementiert wurde, besteht der nächste logische Schritt darin, die gewonnenen Inhalte in einer strukturierten und durchsuchbaren Form abzuspeichern. Hierfür kommt ein n8n-Workflow zum Einsatz, der die Daten aus Crawl4AI automatisch weiterverarbeitet, vektorisiert und in eine Supabase-Datenbank einspeist. Dieser Abschnitt beleuchtet detailliert den gesamten Prozessablauf, beginnend mit der Erstellung einer Sitemap, über das automatisierte Crawlen jeder einzelnen Seite bis hin zur abschließenden Vektorisierung und Speicherung in Supabase.
Die Grundidee hinter diesem Ansatz ist es, eine robuste Datenbasis zu schaffen, die als Fundament für die Retrieval Augmented Generation dient. Durch die Vektorisierung der Texte – also die Umwandlung von semantischen Inhalten in numerische Repräsentationen – können spätere Suchanfragen und semantische Abgleiche äußerst präzise und performant durchgeführt werden. Dies bildet die Basis für den nachfolgenden Chat-Workflow, bei dem die relevanten Dokumentationsinhalte in Echtzeit abgerufen und dem Anwender in Form von KI-generierten Antworten präsentiert werden.
Sitemap einer Softwaredokumentation
Der Ausgangspunkt dieses Workflows ist die Sitemap der Softwaredokumentation. Eine präzise strukturierte Sitemap stellt sicher, dass alle relevanten Seiten erfasst werden und keine Inhalte übersehen werden. Die Sitemap dient dabei als Masterliste, die den Grundstock für den anschließenden Crawling-Prozess legt. Sie bietet außerdem die Möglichkeit unerwünschte Seiten, wie in meinem Fall den Glossar, auszuschließen.
Die Erstellung der Sitemap habe ich mit einem Tool im Internet durchgeführt, da die Dokumentation der gewünschten Software nicht direkt etwas lieferte. Diese habe ich anschließend auf einer meiner Domains gehostet, um sie von n8n einlesen zu lassen.
Jede Seite per Crawl4AI gecrawled
Nachdem die Sitemap erstellt und strukturiert vorlag, übernahm Crawl4AI die Aufgabe, jede einzelne Seite zu crawlen. Hierbei wurden sämtliche Inhalte der Softwaredokumentation automatisiert ausgelesen und in einem einheitlichen Format abgespeichert. Dieser Schritt war von entscheidender Bedeutung, da er die Rohdaten liefert, auf denen im nächsten Schritt die Vektorisierung basiert.
Der Crawling-Prozess musste dabei einiges an Flexibilität aufweisen: Unterschiedliche Seiten enthalten variierende HTML-Strukturen, eingebettete Medien und dynamisch generierte Inhalte. Um diesen Herausforderungen gerecht zu werden, wurde Crawl4AI so konfiguriert, dass es mittels integrierter Selektoren die relevanten Textblöcke extrahiert und irrelevante oder störende Elemente wie Navigationselemente oder Werbung herausfiltert. Ein iterativer Verbesserungsprozess sorgte dafür, dass auch spezielle Seitenformate zuverlässig verarbeitet werden konnten.
Hierbei kam auch fortschrittliche Logik zum Einsatz: Für jede gecrawlte Seite wurde zunächst die URL, der gesamte HTML-Quellcode sowie extrahierte Metainformationen (wie Titel, Veröffentlichungsdatum und Autor) gespeichert. Diese Metadaten dienten später als Basis für die Verknüpfung der Inhalte mit weiteren Informationen in der Datenbank. Ein besonderer Fokus lag dabei auf der Konsistenz und Reproduzierbarkeit der Crawl-Ergebnisse – essenziell, um spätere Abfragen korrekt und präzise durchführen zu können.
Speicherung nach Vektorisierung in Supabase
Der finale Schritt dieses Workflows bestand in der Vektorisierung der crawled Inhalte und deren Speicherung in einer Supabase-Datenbank. Die Vektorisierung erfolgte mittels eines Machine-Learning-Modells, das die semantischen Inhalte der Texte in numerische Vektoren umwandelt. Diese Vektoren ermöglichen anschließend durch mathematische Abgleiche eine präzise Ermittlung semantischer Ähnlichkeiten zwischen verschiedenen Dokumenten. In meinem Fall habe ich ein Modell von OpenAI verwendet, da es vermutlich eines der Ausgereiftesten ist, und so sehr gute Ergebnisse erzielt werden konnten.
Supabase erwies sich hierbei als ideale Lösung, da es als skalierbare, moderne Datenbank nicht nur klassische SQL-Abfragen unterstützt, sondern auch nativ Anbindungen und Erweiterungen für Vektor-basierte Suchen bietet. Die Daten, bestehend aus einem Originaltext, seinen Metainformationen und den zugehörigen Vektor-Repräsentationen, wurden in einer relationalen Datenbank abgelegt und konnten dadurch bei Bedarf schnell und effizient abgefragt werden. Dieser Ansatz wird auch in anderen Projekten wie super-rag von superagent-ai propagiert – dort wird der Mehrwert von Caching und performanten Vektor-Suchabfragen hervorgehoben, um dynamische KI-Anwendungen zu unterstützen.
Der gesamte Vektorisierungsprozess wurde in den n8n Workflow integriert. Sobald Crawl4AI eine Seite erfolgreich gecrawlt hatte, wurde der Text an einen Vektorisierungs-Service weitergeleitet, der das Modell auf die Inhalte anwendete. Die erzeugten Vektoren wurden dann zusammen mit den ursprünglichen Metadaten in Supabase gespeichert. Diese Integration erfolgte über eine RESTful API, wobei alle relevanten Datenfelder (einschließlich der URL, des Titels, des generierten Vektors und weiterer Indexinformationen) in der Datenbank angelegt wurden.
Dank dieses durchdachten Workflows kann nun jede Abfrage, die im späteren Chat-Modul ausgeführt wird, auf die umfangreichen Vektor-Daten zugreifen und kontextuell passende Ergebnisse zurückliefern. Die Vektor-Suche erlaubt es, selbst bei sehr großen Datenmengen schnelle und präzise Suchergebnisse zu erzielen, was den Anwendern in der Praxis einen bedeutenden Mehrwert bietet. Durch den direkten Bezug zu den Metainformationen, die in diesem Schritt ebenfalls erfasst wurden, lassen sich zudem Links zu den entsprechenden Dokumentationsseiten generieren, wodurch Transparenz und Nachvollziehbarkeit erhöht werden.
Zusammenfassend lässt sich sagen, dass die Integration der Daten aus Crawl4AI in eine Vektor-Datenbank via n8n Workflow die Basis für die spätere Retrieval-Augmented Generation bildet. Mit einem soliden Fundament an verarbeiteten und semantisch indexierten Inhalten kann der nächste Schritt – der Chat-Workflow – effizient realisiert werden. Diese eng gekuppelte Kette aus Datenaufbereitung, Vektorisierung und Speicherung stellt die Voraussetzung dar, um auf Grundlage der originalen Softwaredokumentation verlässliche, kontextbezogene Antworten zu generieren.
Teil 3: n8n Workflow für Chat mit RAG Daten über Supabase Vektor Tool und AI Agent
Nachdem sämtliche Inhalte der Softwaredokumentation systematisch erfasst, verarbeitet, vektorisiert und in Supabase abgespeichert wurden, widmet sich der finale Teil des Projekts der Umsetzung eines interaktiven Chats. Ziel dieses Workflows ist es, Anfragen von Anwendern in Echtzeit zu verarbeiten, relevante Dokumentationsinhalte aus der Datenbank abzurufen und diese als kontextuell passende, KI-generierte Antworten zurückzuliefern. Der Aufbau dieses Chat-Systems basiert wieder auf der leistungsstarken Workflow-Automatisierung von n8n und integriert einen speziell entwickelten KI-Agenten, der mittels eines integrierten Tools in Supabase Abfragen ausführt.
Im Detail gliedert sich dieser Chat-Workflow in mehrere Schritte: Zunächst erfolgt ein einfacher Chat-Auslöser, der Anfragen der Nutzer aufnimmt und in den Workflow einspeist. Anschließend wird ein AI Agent aktiviert, der – unterstützt durch das Supabase Vektor Tool – die relevanten Vektor-Daten abruft und analysiert. Ein besonderes Highlight dieses Systems stellt die Verknüpfung der generierten Antworten mit expliziten Links zu den zugrundeliegenden Dokumentationsseiten dar, die aus den Metainformationen hervorgehen. Diese Vorgehensweise gewährleistet, dass der Anwender stets nachvollziehen kann, auf welche Quelle sich die Antwort bezieht.
Einfacher Chat-Auslöser
Der erste Bestandteil des Chat-Workflows ist ein simpler, aber äußerst robuster Chat-Auslöser. Hierbei handelt es sich um einen n8n Node, der Anfragen von Nutzern entgegennimmt – sei es über ein Frontend-Widget, einen API-Endpunkt oder sogar eine Slack-Integration. Der Chat-Auslöser nimmt den rohen Text der Anfrage entgegen und leitet diesen direkt an weitere Verarbeitungsschritte weiter. Dabei wird auch der Kontext der Anfrage, beispielsweise die Identifikation des Nutzers und zusätzliche Metadaten, mit übermittelt, sodass der nachfolgende AI Agent alle relevanten Informationen vorliegen hat.
Technisch erfolgt dieser Schritt über einen HTTP-Request-Trigger in n8n. Sobald eine HTTP-Anfrage eintrifft, wird automatisch ein neuer Workflow-Job gestartet, der die Anfrage verarbeitet und sofort erste Verarbeitungslogiken anstößt. Durch die Nutzung von n8n können auch Rückmeldungen in Echtzeit an den Anwender erfolgen – beispielsweise ein kurzes „Bitte warten, Ihre Anfrage wird bearbeitet …“. Diese Rückkopplung erhöht die Nutzerzufriedenheit und schafft Vertrauen in den Chat-Service.
AI Agent mit Tool um Supabase abzufragen
Im Anschluss an den ersten Trigger kommt der AI Agent zum Einsatz. Dieser Agent übernimmt die semantische Analyse der Eingabedaten und führt eine gezielte Abfrage in der Supabase-Datenbank durch. Ausgestattet mit einem speziell entworfenen Tool, das auf den vektorisierten Daten basiert, sucht der AI Agent nach den dokumentationsrelevanten Inhalten, die am besten zur Nutzeranfrage passen. Dabei spielt vor allem die Fähigkeit zur semantischen Ähnlichkeitssuche eine entscheidende Rolle, denn nur so lässt sich gewährleisten, dass die zurückgelieferten Inhalte auch inhaltlich stimmig sind.
Der AI Agent basiert auf einem hybriden Modell, das klassische Abfrageverfahren mit modernen NLP-Techniken kombiniert. Zunächst wird die Anfrage in einen Vektor überführt, der dann mit den bereits in Supabase gespeicherten Vektor-Repräsentationen verglichen wird. Durch mathematische Distanzberechnungen, wie etwa die Kosinusähnlichkeit, wird der am besten passende Textabschnitt identifiziert. Die Verwendung eines solchen Ansatzes minimiert typische Risiken von Halluzinationen, da die Antwort nicht rein generativ erzeugt, sondern durch einen direkten Bezug zu validierten Dokumentationsinhalten gestützt wird. Die technologische Umsetzung dieses Ansatzes erinnert an Methoden, die auch in anderen Projekten wie super-rag von superagent-ai und arguflow/arguflow zum Einsatz kommen.
Link zu Dokumentationsseiten aus Metainformationen
Ein besonderes Feature des Chat-Workflows ist die Generierung und Integration von direkten Links zu den originalen Dokumentationsseiten. Nachdem der AI Agent die passenden Inhalte identifiziert hat, werden Meta-Daten, wie z. B. die URL der jeweiligen Seite und zusätzliche Beschreibungen, in die Chat-Antwort integriert. Dadurch erhält der Anwender nicht nur eine fundierte, KI-generierte Antwort, sondern auch die Möglichkeit, durch Anklicken des Links vertiefte Informationen direkt aus der Quell-Dokumentation zu erhalten. Dies erhöht nicht nur die Transparenz, sondern fördert auch das Vertrauen in die Richtigkeit und Aktualität der generierten Informationen.
Die technische Umsetzung dieses Features erfolgt über einen weiteren n8n Node, der nach der Abfrage des AI Agents die zugehörigen Metainformationen aus der Datenbank abruft und diese strukturiert in die Antwort einbettet. Dabei werden etwaige Duplikate bereinigt und die Links in einem gut lesbaren Format ausgegeben, sodass sie unmittelbar als Klickbare Verweise erkennbar sind. Dies hat den zusätzlichen Vorteil, dass bei Rückfragen oder Unklarheiten sofort die Originalquelle herangezogen werden kann – ein essenzieller Qualitätsfaktor in technischen Dokumentationen.
Gesamtbetrachtung des Chat-Workflows
Zusammenfassend stellt der Chat-Workflow den krönenden Abschluss des gesamten Projekts dar. Durch die konsequente Kombination von einem einfachen Trigger, einem intelligenten AI Agenten und der Integration von Meta-Informationen wird eine Kommunikationsschicht geschaffen, die sowohl technisch anspruchsvoll als auch nutzerfreundlich ist. Es gelingt, eine Brücke zu schlagen zwischen der komplexen Backend-Logik der Vektorisierung und der intuitiven Interaktion mit dem Endanwender. Dieser mehrschichtige Ansatz stellt sicher, dass Anfragen nicht nur schnell und präzise beantwortet werden, sondern auch stets auf verifizierte Daten zurückgreifen – ein entscheidender Vorteil gegenüber rein generativen Ansätzen, die oft von Halluzinationen und fehlender Quellenbezogenheit geprägt sind.
Die Erkenntnisse aus den bisherigen Schritten – die zuverlässige Datenaufbereitung mittels Crawl4AI, die durchdachte Vektorisierung in Supabase und die flexible Workflow-Automatisierung in n8n – fließen hier zusammen, um ein System zu schaffen, das in der Lage ist, die Herausforderungen moderner Softwaredokumentationen zu meistern. Die kontinuierliche Optimierung der einzelnen Komponenten steht dabei im Fokus, sodass auch zukünftige Erweiterungen und Anpassungen problemlos implementiert werden können. Dieser iterative Verbesserungsprozess ist essenziell, um den ständig wachsenden Anforderungen im Zuge der Digitalisierung und fortschreitender KI-Integration gerecht zu werden.
Hier der Chat-Workflow aus n8n:
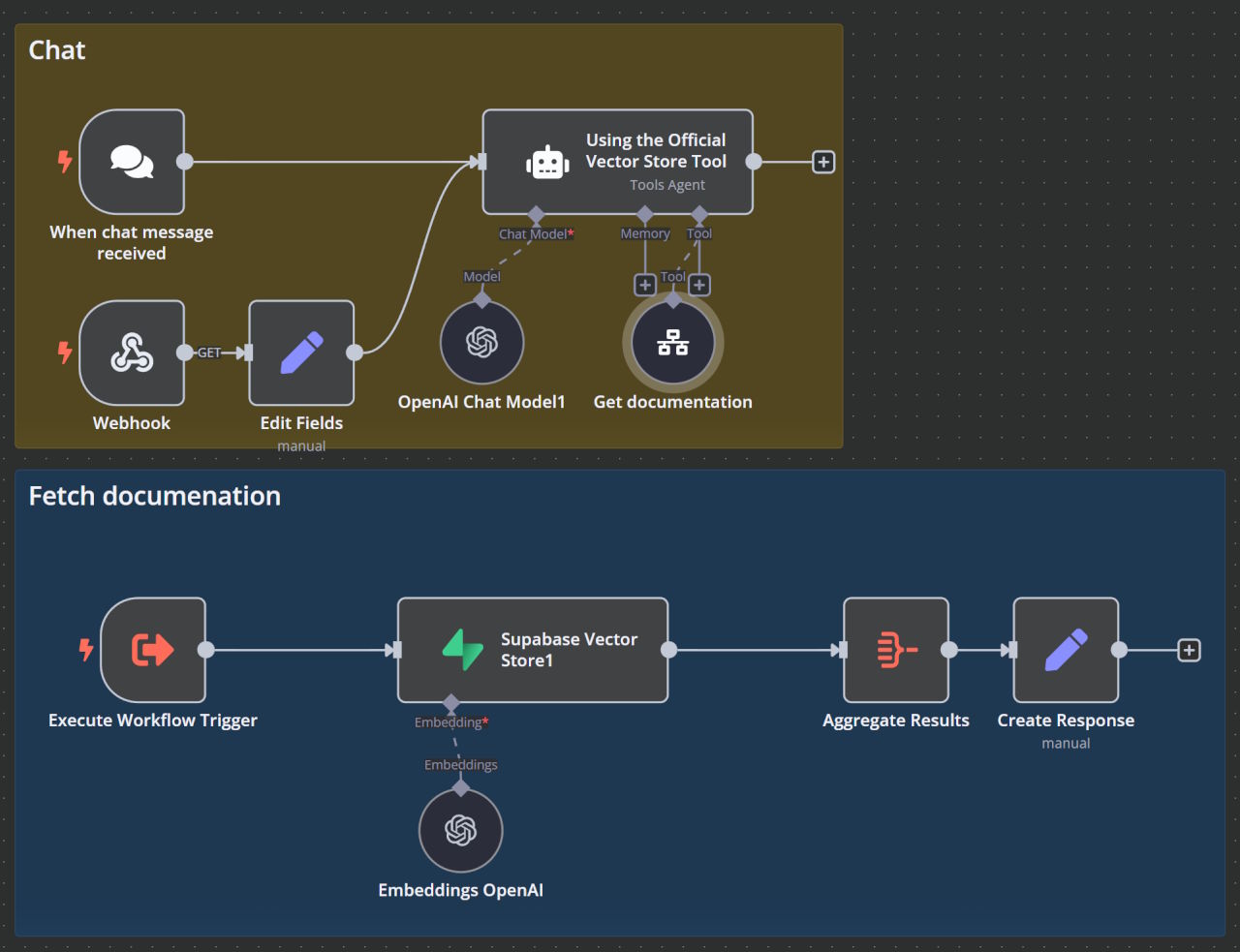
Zusammenfassung
In der abschließenden Betrachtung des Projekts kann ich mit Gutem Gewissen feststellen, dass die entwickelte RAG-Lösung in vielerlei Hinsicht einen entscheidenden Schritt nach vorne darstellt. Die ursprüngliche Herausforderung – die Problematik der Halluzinationen bei generativen KI-Modellen – wurde nahezu vollständig gelöst. Durch die Kombination eines robusten Retrieval-Mechanismus mit einem leistungsstarken generativen Modell konnte ich erreichen, dass alle Antworten auf validierte und kontextuell passende Daten gründen. Dies ist insbesondere in der Umgebung einer komplexen Softwaredokumentation von unschätzbarem Wert, da hier Genauigkeit und Verlässlichkeit oberste Priorität besitzen. Der Rest wird durch entsprechendes Prompting des Chat-Agenten erreicht. Mit etwas rumprobieren habe ich diesen dann auch soweit gebracht, dass er bei Unwissenheit nicht wieder ins Geschichtenerzählen übergeht.
Die daraus resultierende RAG-Lösung ist somit nicht nur eine technische Meisterleistung, sondern gleichzeitig ein praxisnaher Prototyp, der den konkreten Anforderungen im beruflichen Alltag gerecht wird. Durch die iterative Verfeinerung und die konsequente Einbindung moderner Technologien konnte ein System geschaffen werden, das als Referenzmodell für zukünftige Projekte in diesem Bereich dienen kann. Die Möglichkeit, dynamisch auf aktuelle Dokumentationen zuzugreifen, während gleichzeitig das Risiko von Halluzinationen minimiert wird, eröffnet völlig neue Perspektiven in der Verarbeitung und Präsentation technischer Inhalte.
Diese Lösung repräsentiert einen Paradigmenwechsel in der Art und Weise, wie KI-basierte Systeme mit komplexen Datenstrukturen umgehen. Kein System bleibt statisch – kontinuierliche Updates und Optimierungen sind notwendig, um den hohen Ansprüchen moderner Softwarelösungen gerecht zu werden. In meinem Fall war es besonders bereichernd zu sehen, wie sich theoretische Überlegungen und experimentelle Ansätze in eine funktionierende Praxislösung übersetzen ließen.
Die Erfahrungen, die ich im Laufe dieses Projekts sammeln konnte, sind ein Beleg für die technische und methodische Reife, die erforderlich ist, um in der schnelllebigen Welt der KI stets einen Schritt voraus zu sein. Die enge Kooperation der verschiedenen Systemkomponenten und die ständige Optimierung der Arbeitsabläufe tragen dazu bei, dass die Gesamtarchitektur nicht nur stabil läuft, sondern auch flexibel erweiterbar ist. In einer Zeit, in der technologische Entwicklungen in rasantem Tempo voranschreiten, ist es essenziell, Systeme zu entwickeln, die sich nahtlos in bestehende Arbeitsprozesse integrieren lassen und gleichzeitig den höchsten Ansprüchen an Sicherheit und Performance genügen.
Ich hoffe, dass dieser tiefe Einblick in die technische Umsetzung und die integrierten Komponenten eurer Neugierde gerecht wird und als Inspiration für eigene Projekte dient.
Jetzt will ich euch aber nicht länger aufhalten, der Artikel war schon lange genug. Wir lesen uns das nächste Mal auf Next Direction!
]]>